YOLOX [Kor]
Ge et al / YOLOX; Exceeding YOLO Series in 2021 / ArXiv 2021
1. Problem definition

Figure 1. YOLOX 활용 예시
Real-Time Object Detection(실시간 객체 감지)는 기본 수준의 정확도를 유지하면서 실시간으로 객체 감지를 빠르게 수행하는 작업이며, 기존 Object Detection의 방법보다 월등히 빠른 처리 속도가 요구됩니다. Real-Time Object Detection 관련 모델은 이미지 classification과 localization 의 multi-task로 정의되었던 기존 Object Detection 을 하나의 regression 문제로 재해석하여 단일 신경망 구조로 개선한 YOLO(You Only Look Once, CVPR 2016) 모델이 가장 대표적입니다. 이후 YOLO 모델은 여러 시리즈로 이어지면서 실시간 이미지 처리를 위해 최적의 Speed / Accuracy Trade-off를 가지게끔 설계되곤 했습니다. YOLOv5 모델의 경우 13.7ms 만에 48.2% AP를 가지는 최적의 Trade Off를 가지고 있습니다. 본 논문에서 제시하고 있는 YOLOX 모델 역시 Real-Time Object Detection 에 활용될 수 있는 고성능의 object detection model 입니다. 특히, YOLOX-L 모델은 CVPR 2021의 Streaming Perception Challenge (Workshop on Autonomous Driving) 에서 단일 모델 성능만으로 1위를 차지한 모델인 만큼 많은 주목을 받았습니다.
2. Motivation
Related work
YOLO (You Only Look Once) model은 Josept Redmon이 2015년 공개한 version 1 을 시작으로 version 5까지 진행 중에 있습니다. YOLO model의 핵심 아이디어는 classification 과 localization 을 별도의 task로 분리하지 않고, 하나의 regression problem 으로 보아 Convolution Neural Network 을 실시간으로 적용한 것입니다. 이름에서 알 수 있듯이, 이 알고리즘은 객체를 감지하기 위해 신경망의 단일 순방향 전파만 요구됩니다. YOLO 알고리즘의 기본 원리는 세 가지로 구성됩니다.
Residual blocks: 이미지를 동일한 차원의 그리드 셀로 나누고, 모든 그리드 셀은 그 안에 나타나는 개체를 감지합니다. 예를 들어, 객체 중심이 특정 그리드 셀 내에 나타나면 해당 셀이 이를 감지합니다.
Bounding box regression: Bounding box는 이미지 내 객체를 강조하여 표시하는 윤곽선으로, width (bw) / height (bh) / class (c) / bounding box center(bx,by)로 구성됩니다. YOLO는 Bounding box regression을 사용하여 object 의 width, height, class 및 center 를 예측하여 이미지 내 object가 나타날 확률을 나타냅니다.
Intersection over union (IOU): Intersection Over Union는 bounding box가 겹치는 방식을 표현하는 object detection 의 현상입니다. YOLO는 IOU를 사용하여 개체를 완벽하게 둘러싸는 출력 상자를 제공합니다.
주요 YOLO 시리즈의 계보 및 핵심은 아래와 같습니다.

YOLOv3
2018년 4월 발표. Joseph Redmon 이 마지막으로 발표한 YOLO 모델이며, Darknet 53을 기반으로 개발되었습니다.
YOLOv4
2020년 4월 발표. Alexey Bochkousky 로 연구자가 바뀌었으며, 다양한 딥러닝 기법(WRC, CSP ...) 등을 사용해 v3에 비해 AP, FPS가 각각 10%, 12%가 증가하였습니다. CSPNet 기반의 backbone(CSPDarkNet53)을 설계하여 사용했습니다. Anchor-based model 이며, anchor-based 의 경우 클러스터링된 anchor 들은 domain-specific 하며 일반화되기가 어렵고 detection head가 복잡하다는 단점이 있습니다.
YOLOv5
2020년 6월 발표. Glenn Jocher가 발표했으며, v4와 같은 CSPNet 기반의 backbone을 설계하여 사용했고 성능은 비슷하나 경량화된 모델 크기와 속도 면에서 우수합니다. 다만 공식적인 논문으로 발표되지 않고 pytorch 코드 공개만으로 그쳐 공식적인 v5로 명칭을 붙이기에는 논란이 있습니다. 역시 anchor-based 로 최적화된 모델입니다.
PP-YOLO
2020년 7월 발표. Shing Long이 발표했으며, v4보다 정확도와 속도가 더 높습니다. v3 모델을 기반으로 하나, Darknet3 backbone을 ResNet 으로 교체했으며 오픈소스 machine learning framework인 PaddlePaddle 기반으로 개발되었습니다.
Idea
최근 학계에서는 anchor-free detectors, advanced label assignment strategies, end-to-end (NMS-free) detectors 등 다양한 object detection 기법이 새로 제시되었지만, 기존 YOLO 시리즈에 적용되지는 않았습니다. 본 논문은 이러한 기법들을 기존 YOLO 모델을 개선시키는 데에 적용하고 성능을 개선한 모델인 'YOLOX'을 제안하고 있습니다. YOLOv4와 YOLOv5의 파이프라인은 Anchor Based 위주로 최적화가 진행되어있기 때문에, 보다 범용적인 성능은 오히려 떨어질 수 있다고 판단한 본 논문의 저자들은 YOLOv3-SPP와 DarkNet53 을 baseline 으로 삼았습니다. 이에 Decoupled head 와 Anchor free, Multi positive, SimOTA 방식을 적용하여 최신 object detection 기술들을 적용하고 성능을 개선하였습니다.
3. Method

YOLOX는 기본적으로 Input - Backbone - Neck - Dense Prediction의 구조를 가집니다. Darknet53의 Backbone 아키텍쳐를 통해 Feature Map을 추출하며, SPP(Spatial Pyramid Pooling) Layer를 통해 성능을 개선합니다. FPN을 통해 Multi-Scale Feature Map을 얻고 이를 통해 작은 해상도의 Feature Map에서는 큰 Object를 추출하고 큰 해상도의 Feature Map에서는 작은 Object를 추출하게끔 한 Neck 구조를 차용하였습니다. 그리고 Head 부분에서는 기존 YOLOv3~v5 와 달리 Decoupled Head를 사용했습니다.
Decoupled Head
YOLOv3에서는 하나의 Head에서 Classification과 Localization을 함께 진행하였으나, 이후 여러 연구를 통해 Object detection task 에서 classification 과 regression task 가 서로 상충된다는 사실이 밝혀졌습니다. Classification 에는 Fully Connected Layer가 효과적이지만, 반면에 Localization에는 Convolution Head가 보다 적절한데 이 두가지가 서로 상충되기 때문입니다. 또한 Coupled detection 의 경우 성능도 저하됩니다. YOLOX에서는 decoupled head를 사용하여 classification엔 Fully Connected Head를, Localization에는 Convolution Head를 적용함으로써 성능을 향상시켰습니다.
Anchor-free
Anchor Box란 입력 이미지 혹은 영상에 대해 객체 감지를 위해 설정한 Bounding Box 중 각 픽셀을 중앙에 두고 크기와 종횡비가 서로 다르게 생성된 bounding box를 말합니다. 많은 Object Detection 모델들이 Anchor-based로 미리 세팅해놓은 수 많은 anchor에서 category를 예측하고 coordinates를 조정하는 방식을 사용했지만, 최근에는 FPN과 Focal Loss의 출현으로 인해 anchor-free detector 방식에 대한 연구가 진행되고 있습니다. Anchor-free detector에는 두 가지 방법이 있는데, 키 포인트를 이용하여 object의 위치를 예측하는 keypoint-based 방법과 object의 중앙을 예측한 후 positive인 경우 object boundary의 거리를 예측하는 center-based 방법이 있습니다. 기존 Anchor 기반의 Detector들은 비록 그 성능은 뛰어날 수 있지만, 개발자들이 직접 Heuristic 하게 Tuning을 진행해주어야 하는 불편함이 존재합니다. 또한 그렇게 Tuning된 Anchor Size 또한 특정 Task에 종속적이므로 General한 성능은 떨어지는 이슈가 있었습니다. 이러한 anchor-free detector은 anchor에 다양한 Hyperparameter들을 Tuning해야 하는 필요성이 없으면서 anchor-based detector와 비슷한 성능을 얻기 때문에, object detection 분야에서 더 General 하게 성능을 낼 수 있는 잠재력 있다고 여겨집니다.
Multi positives
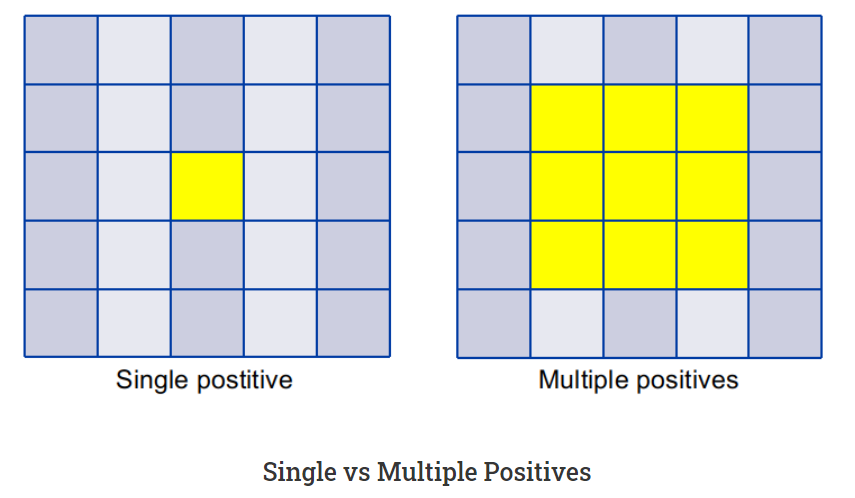
기존 YOLOv3의 Assigning 방식을 그대로 유지한다면 중앙 위치 값 1개 만을 Positive Sample로 지정하여야 하지만, 이는 그 주변에 예측한 다른 데이터들을 모두 제외하게 되는 효과를 가집니다. 따라서 Positive Sample을 중앙 위치 값 주변 3x3 사이즈로 모두 지정함으로써 이러한 고품질의 예측 값에 대해서 이득을 취할 수 있도록 합니다 (FCOS의 Center Sampling 기법). 이렇게 positive Sample을 증강해줌으로써, 심각한 class 불균형 문제를 어느 정도 상쇄시킬 수 있습니다.
SimOTA

Label assignment는 sample data 중에 어떤 것이 positive이고 negative 인지 ground truth object에 할당해주는 것입니다. YOLOX는 객체 탐지에서 Label Assignment를 각 지점에 대하여 Positive과 Negative를 할당해주는 방식으로 Label assign 방식을 개선시켰습니다. Anchor Free방식은 Ground Truth의 박스 중앙 부분을 Positive로 처리하는데, 문제는 label 여러 개가 하나의 bounding box에 겹칠 때입니다. 이런 경우 단순히 point by point가 아닌 Global Labeling이 필요한데, 이를 최적화하는 방식으로 저자는 SimOTA를 적용했습니다. OTA(Optimal Transportation Algorithm)은 Sinkhorn-knopp iteration등의 방법을 통해서 최적의 값을 찾아내는데 사용되는데, 이러한 iteration으로 인해 약 25%의 추가 학습 연산이 필요하게 됩니다. 이는 약 300 Epoch의 학습이 필요한 YOLOX에게 꽤나 큰 오버헤드이므로, 저자들은 이를 간단하게 iteration 없이 수행하는 Simple OTA(SimOTA)를 적용하였으며 AP 45.0%를 47.3%로 향상시키는 효과가 있었습니다. ground truth와 prediction의 cost 함수는 아래와 같습니다.
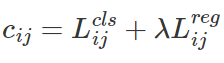
4. Experiment & Result
Experimental setup
Dataset
COCO train2017
Baselines
YOLOv3-SPP + DarkNet53
Training setup
Initial learning rate: 0.01, lr X BatchSize/64
batch size: 128
weight decay: 0.0005, SGD momentum: 0.9
Result

YOLOX는 Streaming Perception Challenge (WAD at CVPR 2021)에서 단일 모델만으로 1위를 달성한 SOTA 모델이며, 여태 나온 YOLO Series 모두를 능가하는 AP를 얻었습니다. 기존 YOLO 모델들과 마찬가지로 속도와 성능간의 Trade Off가 존재하지만, 다른 모델들과 비교했을 때 높은 성능과 FPS를 동시에 얻어내는 모습을 보입니다.
5. Conclusion
본 논문의 저자들은 YOLO에 최신 Object Detection 기법들을 적용한 YOLOX를 소개했습니다. Decoupled Head, Multi-Postive, SimOTA, Strong Augmentation 등 최신 연구 내용을 바탕으로 YOLOv3 기반의 모델을 효과적으로 향상시켰으며, YOLOv5에 적용했을 때도 유의미한 성능 향상을 보입니다. Anchor Free 방식을 적용하여 General한 성능을 보장하며, 모델 구현자로 하여금 Anchor와 관련된 다양한 Hyperparameter를 Tuning할 필요없이 간편하게 학습이 가능하도록 했다는 의미가 있습니다.
Take home message (오늘의 교훈)
YOLOX는 Decoupled Head, Anchor-Free, Multi-Postive, SimOTA, Strong Augmentation 등 최신 연구 내용을 바탕으로 YOLOv3 기반의 모델을 효과적으로 향상시켰으며, YOLOv5에 적용했을 때도 유의미한 성능 향상을 보입니다.
Author / Reviewer information
Author
박지윤 (Jiyun Park)
Affiliation: KAIST Graduate School of Culture & Technology
Contact : june@kaist.ac.kr
Reviewer
Korean name (English name): Affiliation / Contact information
Korean name (English name): Affiliation / Contact information
...
Reference & Additional materials
Citation
Ge, Z., Liu, S., Wang, F., Li, Z., & Sun, J. (2021). Yolox: Exceeding yolo series in 2021. arXiv preprint arXiv:2107.08430.
Wu, Y., Chen, Y., Yuan, L., Liu, Z., Wang, L., Li, H., & Fu, Y. (2020). Rethinking classification and localization for object detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 10186-10195).
Redmon, J., & Farhadi, A. (2018). Yolov3: An incremental improvement. arXiv preprint arXiv:1804.02767.
Zhang, S., Chi, C., Yao, Y., Lei, Z., & Li, S. Z. (2020). Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 9759-9768).
References
https://danaing.github.io/computer-vision/2021/08/26/YOLOX.html
Last updated