SegFormer [Kor]
xie et al. / SegFormer; Simple and Efficient Design for Semantic Segmentation with Transformers / NeurIPS 2021
1. Problem definition

Figure 1. Semantic segmentation 예측 결과
Semantic segmentation은 이미지 내의 모든 픽셀을 여러개의 하위 클래스로 분류해, 이미지를 의미있는 객체 단위로 나누어 주는 task입니다. 이를 통해 우리는 이미지 영상 내 표현을 좀 더 의미있고 해석하기 쉬운 것으로 단순화하거나 변환할 수 있게 됩니다. semantic segmentation은 특히 영상에서 물체와 경계(선, 곡선)를 찾는데 사용 될 수 있어, 자율주행이나 의료 영상 분할 등 여러 분야에서 활용가치가 높아 활발히 연구가 진행되고 있습니다.
최근 natural language processing (NLP) 에서 큰 성공을 거둔 self-attention, Transformer 구조를 semantic segmentation task에 적용시키는 연구가 많이 진행되고 있는데요, 이러한 연구들 중 하나인 Segformer는 어떠한 방법으로 Semantic segmentation task에 transformer 구조를 적용시키려 하였는지 소개해 보도록 하겠습니다.
2. Motivation
이전에도 PVT(Pyramid Visoin Transformer, Swin Transformer, SETR 와 같은 transformer-based segmentation 모델들이 등장 했으나, 모두 endcoder에만 transformer 구조를 적용하고, decoder 는 기존에 많이 사용되는 CNN-based decoder 구조를 유지하고 있습니다.
이전 연구들과 다르게 이번에 소개드릴 SegFormer 논문에서는 encoder 와 decoder 모두에 transformer를 사용하여 단순하면서도, 효율적이고, 성능까지 높은 강력한 모델 디자인을 제안하였습니다.
Related work
Semantic Segmentation Semantic segmentation 은 이미지 분류 task의 확장판이라고 할 수 있는데, 단순히 이미지 레벨에서의 분류가 아닌 픽셀 영역에서의 분류 라고 할 수 있습니다. 초기 CNN 기반의 FCN(fully convolution network)이 end-to-end manner 로 semantic segmentation의 문을 열었고, 그 후 많은 연구자들이 FCN의 후속연구로서 성능을 향상 시켜왔습니다. 기존의 연구들은 receptive field를 확장 시키거나, contextual information이나, boundary information을 추가로 더해주는 등의 방식으로 연구가 진행 되었으며, 최근 다양한 attention modules을 접목시킨 연구들도 등장했습니다. 이러한 연구들은 Semantic segmentation의 성능을 대폭 향상시켰지만, 이러한 성능 향상은 까다롭고 복잡한 계산이 수반되기 때문에 컴퓨터 resource에 크게 의존 할 수 밖에 없습니다. 보다 최근의 방법으로 segmetnation을 위한 Transformer 기반 아키텍쳐이 등장했지만, 이러한 아키텍쳐 역시 복잡한 계산이 수반되어 앞의 문제에서 자유로울 수 없다는 한계점을 가지고 있습니다.
Transformer backbones Image classification task 에서 Vision Transformer (ViT) 는 classification에서 sota를 달성하는 등 우수한 성능을 보여주었으며 특히 ViT는 각 이미지를 token으로 나누어 여러 Transformer layer가 이를 classficiation을 위한 representation을 학습하게 됩니다. 이후 ViT를 잇는 후속 연구로 데이터를 효율적으로 학습하는 학습전략과 distillation을 접목한 DeiT부터 T2T ViT, CPVT, TNT, CrossViT, LocalViT등 여러 아키텍쳐들이 등장했습니다.

Figure 2. PVT 구조와 기존 아키텍쳐와의 구조 비교
Image classification이에외도, PVT [8]는 pyramid 구조를 Transformer에 접목해 Transformer가 detection이나 segmentation과 같은 dense prediction task에서도 좋은 성능을 보여 잠재적 성장 가능성을 입증했습니다. 그이후로 Swin [9], CvT [58], CoaT [59], LeViT [60], Twins [10] 등 다양한 아키텍쳐들은 이미지 features의 국지적 연속성(local continuity)을 개선하고, 트랜스포머의 고유 요소중 하나인 고정된 크기의 position embedding을 제거하면서 성능을 향상시켰습니다.
Transformers for specific tasks 트랜스포머를 특정한 Task에 접목시킨 시발점은 DETR 이라 할 수 있습니다. DETR은 트랜스포머를 활용해 기존 detection에서 필수 였다고 할 수 있는 NMS(Non-Maximum Suppression)를 없애고 end-to-end 프레임 워크를 구축하였습니다. 이 외에도 tracking, super-resolution, ReID, Colorization, Retrieval,multi-modal learning,semantic segmentation 등 여러 task에서도 트랜스포머를 접목시키려는 시도들이 있었습니다.
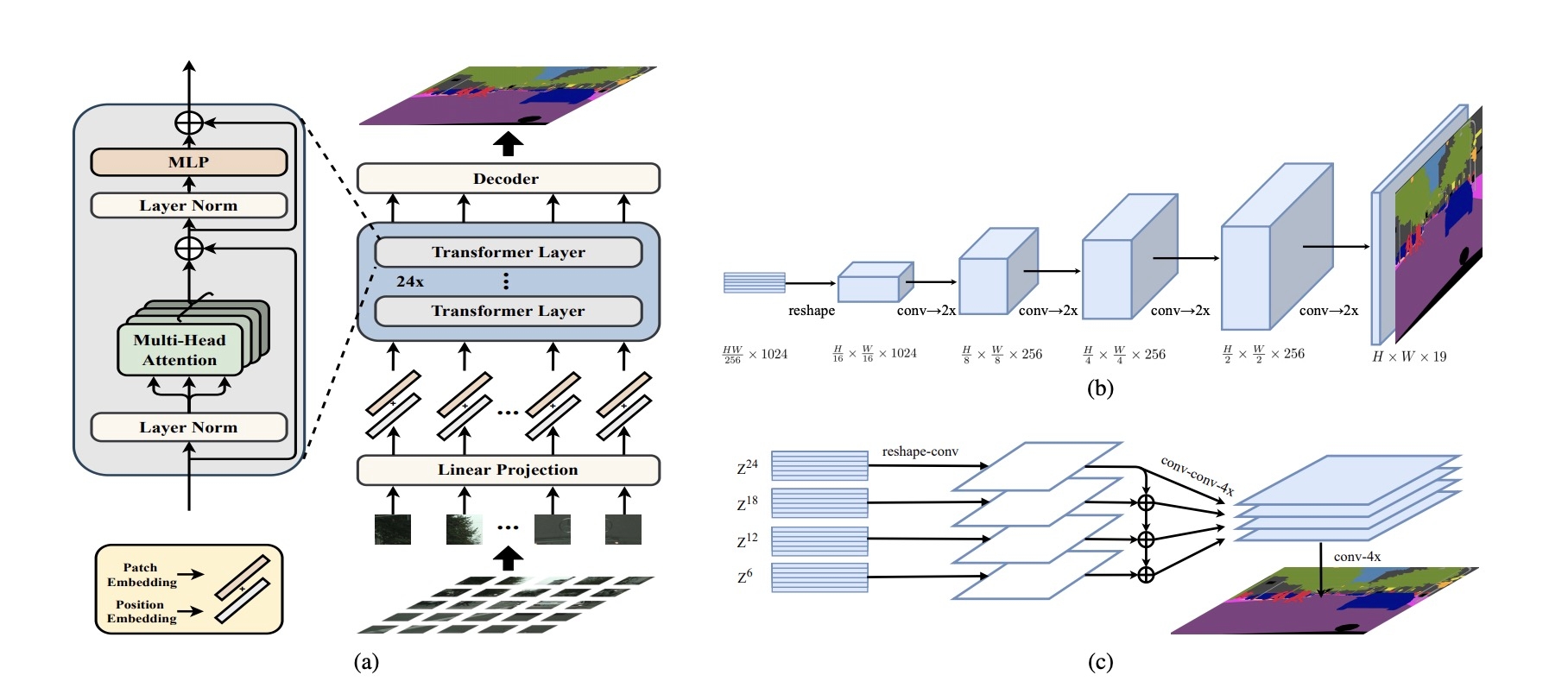
Figure 3. SETR의 네트워크 구조
특히 Semantic segmentation에서는 SETR이라는 네트워크가 등장해 기존의 성능을 월등히 향상 시켰는데요, SETR은 대표적인 vision transformer인 ViT를 features extractor를 backbone 네트워크로 채택하였습니다. 하지만 앞선 트랜스포머 기반 네트워크들은 높은 연산량을 기반으로 두기 때문에 메모리 비효율적이며, 실시간 응용이 불가능해 배포상의 어려움이 수반됩니다.
Idea
본 논문에서는 기존 ViT 기반의 SETR의 positional-encoding으로 인해 single-scale의 low-resolution feature 만을 이용하여 multi-scale feature 를 활용할 수 없다는점, 고해상도의 이미지에서는 계산 비용이 큰 점을 지적하면서, hierarchical 구조의 positional-encoding-free 트랜스포머 인코더 구조와 복잡하고, 많은 연산량을 필요하는 구조에서 탈피한 lightweight All-MLP decoder를 제안 하였습니다.
3. Method
3.1. hierarchical Transformer encoder
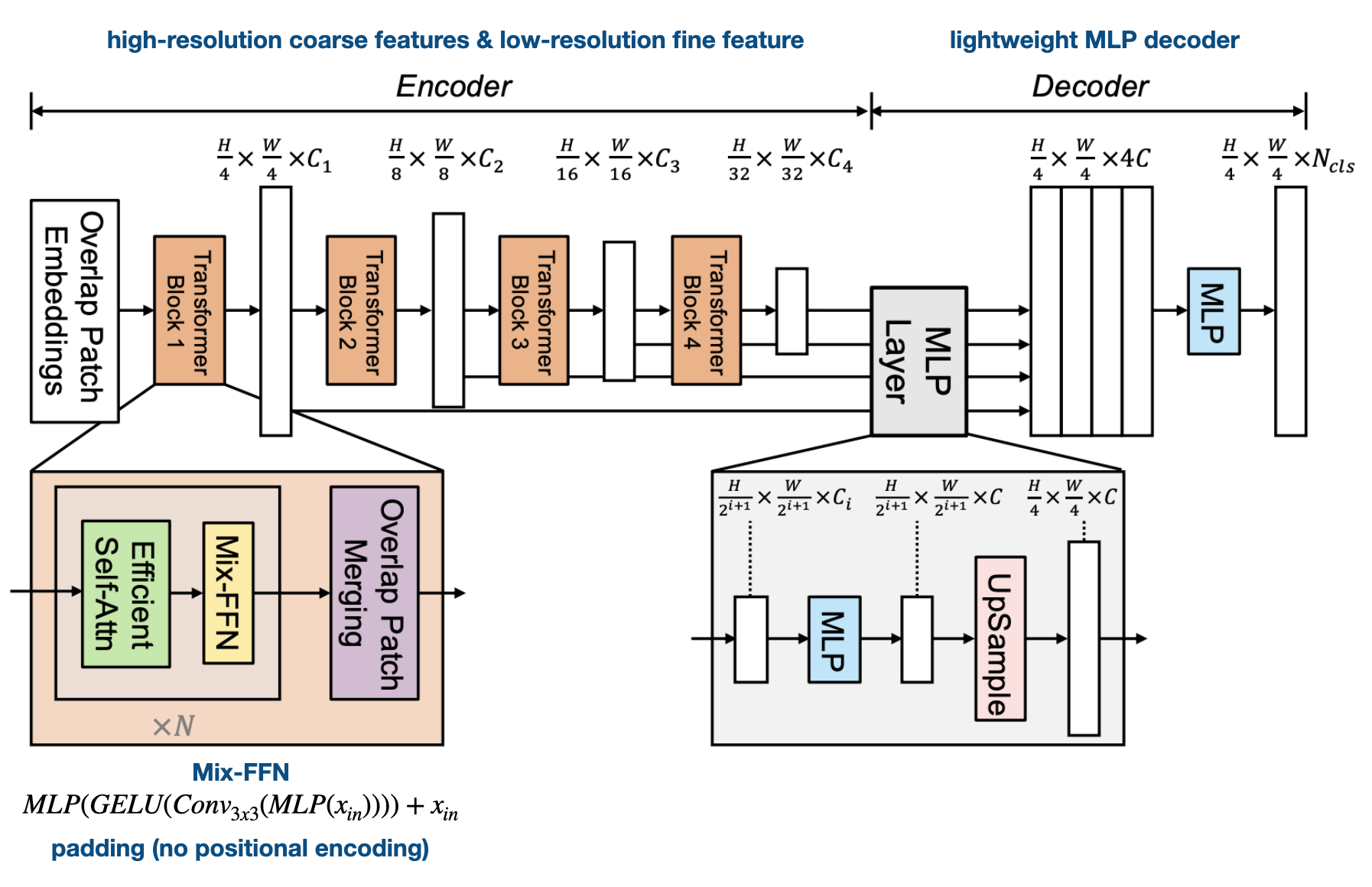
Figure 3. hierarchical Transformer encoder 구조
모델의 전체적인 구조는 위 그림과 같습니다. 인코더는 4단계의 hierarchical Transformer 구조로 구성되있습니다. 이전 연구인 SETR은 앞서 설명해 드린바와 같이 ViT기반 인코더로 인해 single-resolution feature map을 생성했었는데, SegFormer에서는 계층적인 구조로 CNN과 유사하게 high-resolution coarse feature부터 low-resolution fine feature까지 multi-scale 의 feature representation을 얻을 수 있습니다.

Transformer Block은 Efficient Self-Attn과 Mix-FFN, Overlap Patch Matching 으로 구성되어있습니다. Overlap Patch Matching은 오른쪽 그림처럼 convolution network를 사용해 stride, padding으로 overlap 되는 patch를 샘플링을 합니다.이를 통해 local continuity를 유지한 채 hierarchical feature map을 구성 할 수 있게 됩니다.
특히 Efficient Self-Attn 에서는 PVT와 유사하게 K(key)의 dimension reduction을 통해서 complexity를 줄였습니다. Mix-FFN는 convolution layer을 가운데 넣어서 zero padding으로 positional encoding을 대신할 수 있도록 하였습니다. 기존의 positional encoding의 resolution은 고정되어 있다는 단점이 있는데, zero padding을 사용하면 train 과 test의 resolution이 달라도 성능에 크게 영향이 없으면서도 resolution을 키울수 있어, multiscale feature 생성이 가능해집니다.
3.2. lightweight All-MLP decoder
decoder는 굉장히 심플한 구조를 가지고 있는데요, 각 transformer 블록에서 나온 4가지 크기의 multi-level feature들은 MLP Layer를 통과해서 channel dimension을 맞추기 위해 upsample한 뒤 concatenate 됩니다. 합쳐진 multi-scale feature 들은 MLP 레이어를 통과하여 최종 segmentation map을 도출합니다.
SegFormer는 이러한 MLP 레이어로만 구성된 경량 디코더를 통해 일반적으로 semantic segmentation task에서 흔히 사용되던 hand-craft하고 계산적으로 까다로운 decoder filter등의 부가적인 요소들에서 해방되었습니다. 이러한 간단한 디코더가 가능했던 핵심 요소는 바로 계층적 트랜스포머 인코더가 기존의 CNN 인코더보다 더 큰 유효 수용 필드(Effective Receptive Field ;ERF)를 가지고 있다는 점에 있습니다.
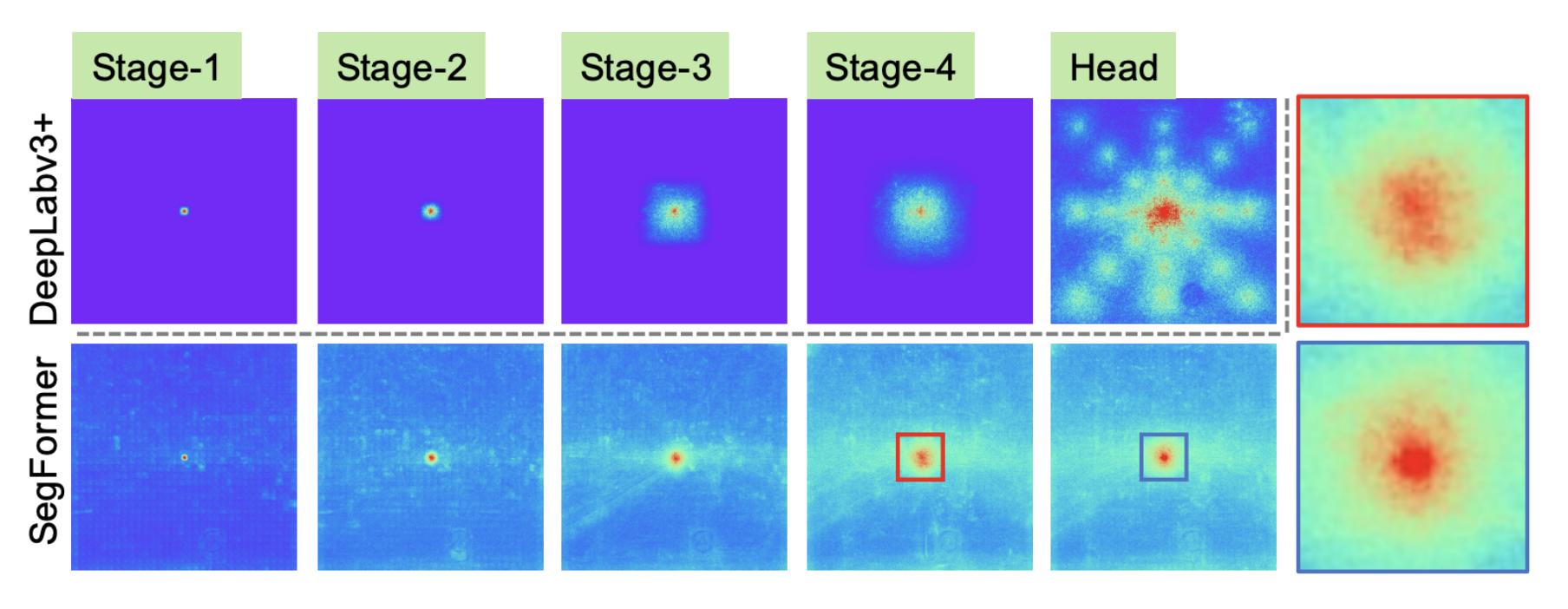
Figure 5. Segformer와 CNN 기반 네트워크의 유효 수용 필드 시각화 결과 비교
위 그림은 대표적인 CNN 기반 네트워크인 DeepLabv3+와 SegFormer의 effective receptive field를 시각화 결과를 비교한 결과 입니다. SegFormer의 receptive field가 훨씬 큰 것을 볼 수 있습니다. SegFormer의 경우 초기 단계 (stage 1-2)에서 컨볼루션과 유사한 local attentions을 보임과 동시해 4단계에서 global context를 효과적으로 출력하는 것을 볼 수 있는데요, 특히 위 그림에서 오른쪽 끝의 확대된 패치와 같이 MLP 헤드(파란색 상자)에서의 ERF는 4단계(빨간색 상자)보다 더 강하게 강조된 local, global attention을 보입니다. 이를 보아 segformer은 단순한 MLP 디코더를 통해 local 및 global attention을 강하면서도, 동시에 유도할 수 있음을 확인할 수 있습니다.
4. Experiment & Result
Experimental setup
Dataset : Cityscapes, ADE20K, COCOStuff
Baselines : SETR, DeeplabV3
Training setup :
Imagenet-1K pretrained encoder with randomly initialize decoder
augmentation : random resize with ratio 0.5-2.0, random horizontal flipping, and random cropping
Learning rate : 0.00006 with poly LR schedule
Optimizer : AdamW
Training method :
160K : Cityscapes, ADE20K
80K : COCOStuf
Batch size : 16 ADE20K COCO-Stuff, 8 Cityscapes
Evaluation metric : mIoUs
Result
Ablation study
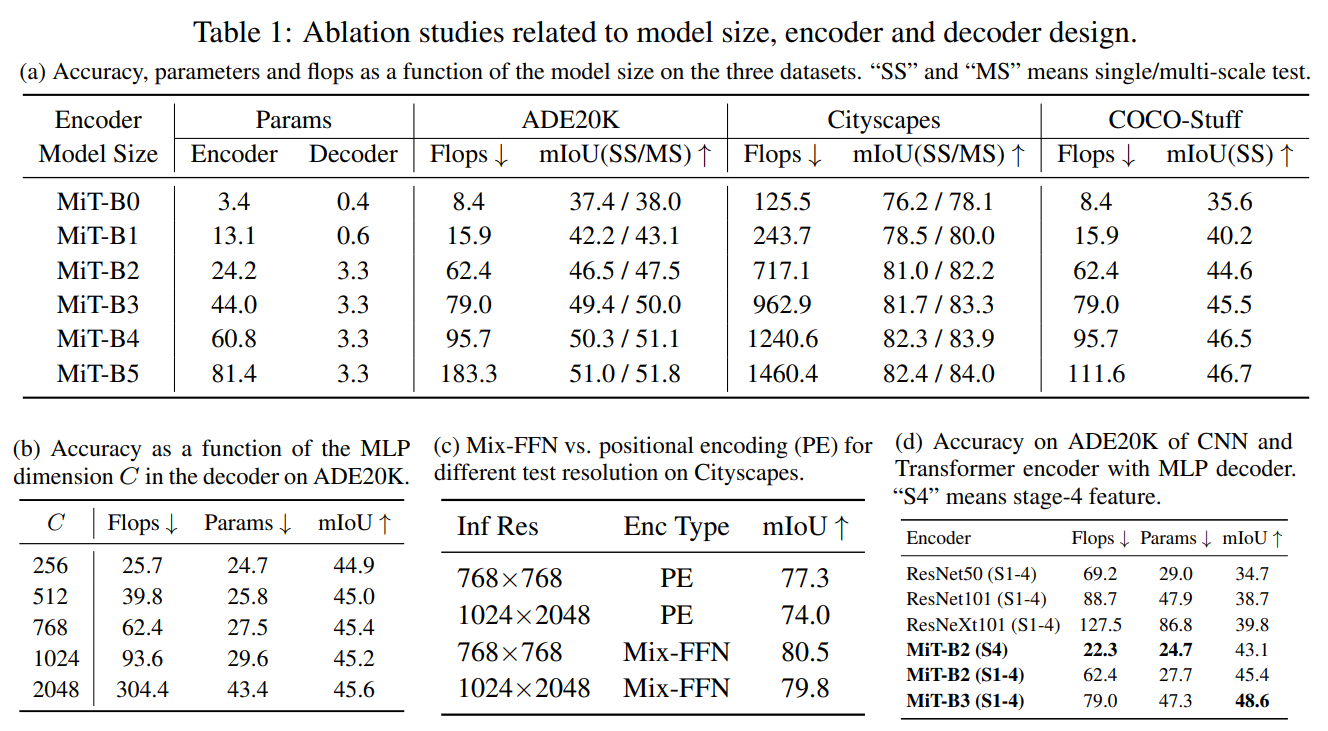
Table 1. Ablation study results
Influence of the size of model. 디코더의 파라미터 수를 보았을때, 경량 모델인 (MiT-B0)의 디코더의 파라미터는 0.4M이며, MiT-B5 인코더의 경우 디코더는 모델의 전체 파라미터 수의 최대 4%만 차지합니다. 이는 굉장히 경량화된 디코더 구조라 할 수 있습니다. 성능을 보아도, 전반적으로 모든 데이터 세트에서 인코더 크기를 늘렸을 때 성능이 향상되었습니다. 이를 보아 경량 모델인 SegFormer-B0은 우수한 성능을 유지하면서도 연산량이 적어 효율적이고, 실시간 애플리케이션에 적용가능성을 보여주었습니다. 또한 가장 큰 모델인 SegFormer-B5는 세 데이터 세트에서 가장 우수한 결과를 달성하여 Transformer 인코더의 잠재력을 보여줍니다.
Influence of C, the MLP decoder channel dimension. 표 1b에서는 MLP decoder channel dimension에 따른 성능을 비교한 결과입니다.C = 256이었을 때 경쟁력있는 성능과 계산 비용임을 알 수 있습니다. 채널이 증가할 수록 성능은 증가하지만, 성능증가 폭 대비 플롭, 파라미터 증가 폭이 커 비효율적인 모델로 이어집니다.
Mix-FFN vs. Positional Encoder (PE). 표 1c 와 같이, 주어진 이미지 해상도에 대해, Mix-FFN은 Positional Encoder을 사용하는 것보다 확실히 우수한 성능을 보여줍니다. 또한, Mix-FFN은 테스트 해상도의 차이에 덜 민감함을 보여줍니다. Positional Encoder의 경우 낮은 해상도에서 정확도가 3.3%나 하락합니다.하지만 Mix-FFN을 사용하면 성능 저하가 0.7%만 하락합니다.이를 보았을때, 제안된 Mix-FFN을 사용하는 것이 Positional Encoder보다 해상도의 영향에 덜 민감하면서도 더 강력한 인코더를 만듬을 확인할 수 있습니다.
Effective receptive field evaluation. 표 1d는 MLP-디코더가 CNN 기반 인코더가 아닌 Transformer기반 인코더와 결합하는 것이 더 높은 정확도를 가짐을 시사합니다. 직관적으로, CNN은 Transformer보다 receptive field가 작기 때문에, MLP-decoder 로는 global 영역에 대한 추론을 하기에 충분하지 않습니다. 또한 Transformer 인코더의 경우 high-level feature 만 사용하는 것이 아닌 low-level local features 과 high-level non-local features을 결합되어야 함을 알 수 있습니다.
ADE20K
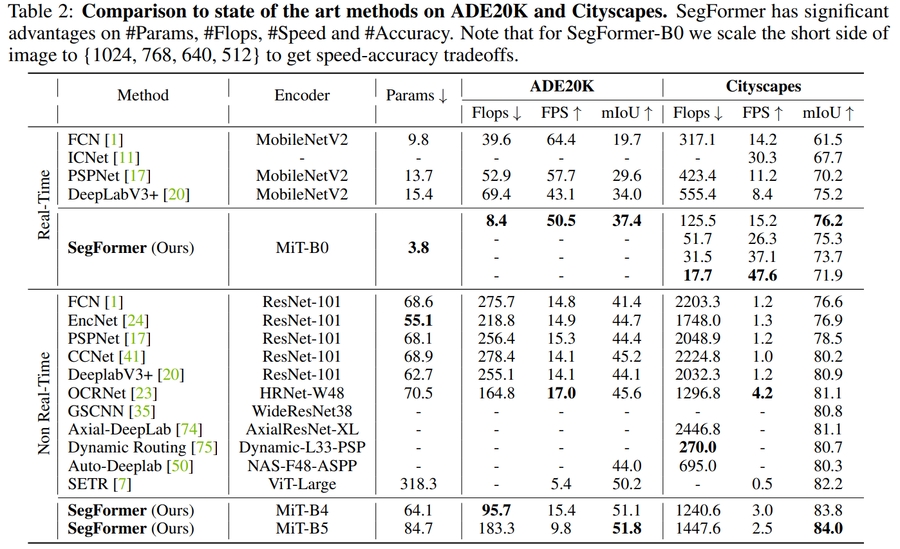
Table 2. ADE20K study results
CityScape
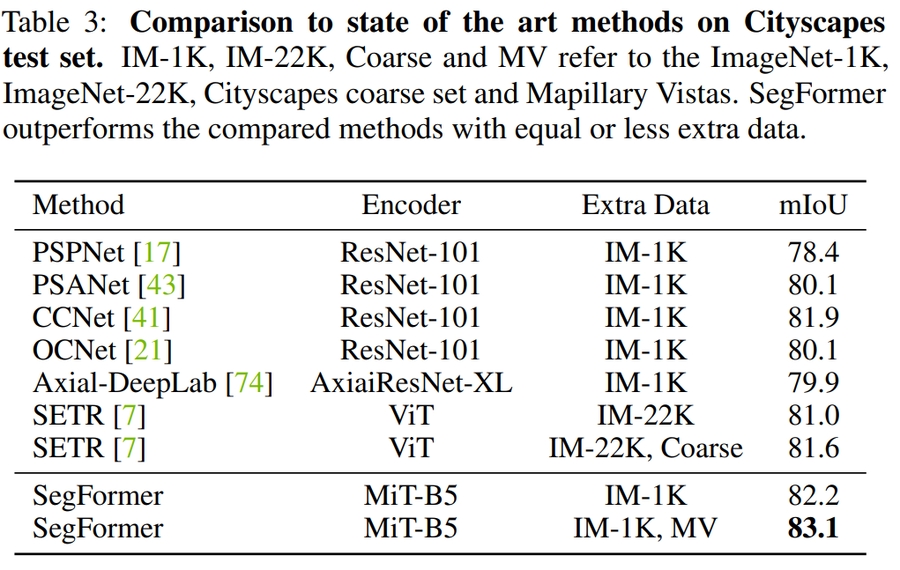
Table 3. CityScape study results
COCO
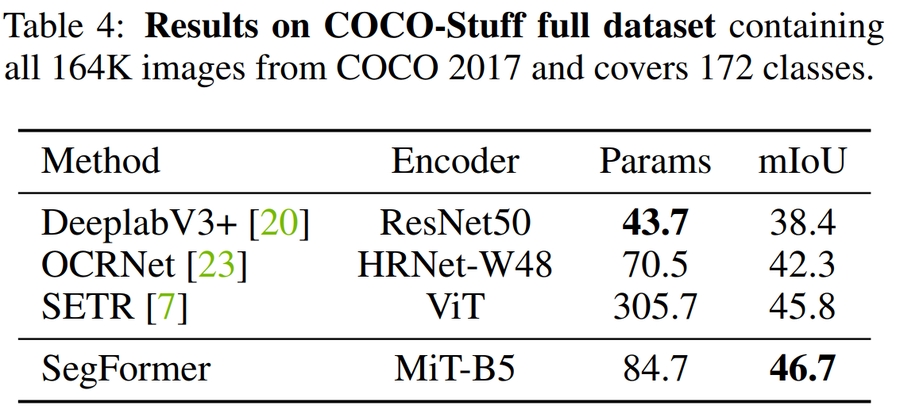
Table 4. COCO study results표 2,3,4는 ADE20K 및 CityScape,COCO 데이터 셋에 대한 파라미터수, FLOPS, 지연 시간 및 정확성을 포함한 결과를 요약합니다. 이를 보았을때,제안된 Segformer가 기존의 CNN 기반 방법들에 비해 적은 파라미터 수를 유지하면서도, 높은 성능을 보여 고효율의 고성능 모델임을 확인할 수 있습니다.
5. Conclusion
본 논문에서는 Positional Encoding이 없는 계층적 트랜스포머 인코더와 경량 All-MLP 디코더 구조의 굉장히 간단하고 강력한 Semantic segmentation 방법인 SegFormer를 제안하였습니다. 이전 방법에서 흔히 볼 수 있는 복잡한 네트워크 구조를 탈피하면서도 효율성과 성능을 모두 향상된 새로운 모델이라 할 수 있습니다. SegFormer는 일반적인 데이터 세트에서 최고 성능을 달성했습니다.
Take home message
기존 제안된 방법들의 단점을 분석하고 개선하는 것과, 제안하는 방법의 우수성을 입증하기 위해 필요한 요소들이 무엇인지 생각하는 것이 중요하다고 생각합니다.
Author / Reviewer information
Author
박진영 (Jinyoung Park)
Affiliation (KAIST EE / NAVER)
Contact : jinyoungpark@kaist.ac.kr
Reviewer
Reference & Additional materials
Xie, E., Wang, W., Yu, Z., Anandkumar, A., Alvarez, J. M., & Luo, P. (2021). SegFormer: Simple and efficient design for semantic segmentation with transformers. Advances in Neural Information Processing Systems, 34.
Wang, W., Xie, E., Li, X., Fan, D. P., Song, K., Liang, D., ... & Shao, L. (2021). Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 568-578).
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., ... & Houlsby, N. (2020). An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929.
Zheng, S., Lu, J., Zhao, H., Zhu, X., Luo, Z., Wang, Y., ... & Zhang, L. (2021). Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 6881-6890).
Last updated