# Show, Attend and Tell \[Kor]
**English version** of this article is available.
### 1. Problem definition
이 모델은 Encoder-Decoder 구조와 attention mechanism을 더하여 image captioning task를 수행합니다!
* image captioning이란?
간단히 말하면, image captioning은 image를 모델에 입력으로 넣었을 때 모델이 caption을 달아 image를 설명하는 task를 말합니다. 이런 작업을 하기 위해서는 일단 image 안에 무슨 object가 있는지 판별할 수 있어야 하고, 그 image 형식으로 표현된 object를 우리가 사용하는 언어, 즉 Natural language에 연결할 수 있어야 합니다.
데이터는 그림(visual), 문자(text), 음성(auditory) 등 다양한 형태로 표현될 수 있는데, 이렇듯 여러 데이터 type (mode)를 사용해서 모델을 학습시키는 형태를 Multi-modal learning이라고 합니다. 따라서 이 고전적인 논문에서 다룰 모델도 visual information (image)과 descriptive language (natural language)를 map하여 image captioning을 수행한다는 면에서 multi-modal learning이라고 할 수 있습니다.

* 이 모델은 encoder-decoder 구조와 attention based approach를 차용합니다. 이에 대해서는 Related work 섹션에서 자세히 설명할게요. 논문에서 다룬 모델이 수행하는 task를 간단히 설명하면,
(1) 2-D image를 input으로 받아,
(2) 그에 대해 CNN으로 feature extraction을 수행하여 input image에 대응되는 feature vector를 얻고,
(3) LSTM에서 feature vector와 attention mechanism을 사용하여 ,
(4) word를 generation하는 방식으로 image를 captioning합니다.
### 2. Motivation
#### Related work
* Neural net 이전 image captioning 방법들
Neural net을 image captioning task에 사용하기 전까지, 크게 두 흐름이 있었습니다. 그러나 이미 Neural Net을 차용하는 방식에 크게 밀려 더 이상 사용하지 않는다고 합니다.
* object detection과 attribute discovery를 먼저 진행한 후, caption template을 생성하는 방식
참조: Kulkarni et al. (2013), Li et al. (2011), Yang et al. (2011)
* captioning 하려는 image와 비슷하지만 이미 captioned image를 DB에서 찾아낸 후, 우리의 image의 query에 맞게 찾아낸 이미지의 캡션을 수정하는 방식
참조: Kuznetsova et al., 2012; 2014
* The encoder-decoder framework (sequence-to-sequence training with neural networks for machine translation)
machine translation 분야의 주류가 된 방식으로, 당시에는 seq-to-seq training을 주로 RNN에서 수행하는 구조를 사용했습니다. image captioning은 그림을 'translating'하는 작업과 비슷하기 때문에, Cho et al., 2014에서 다룬 encoder-decoder framework for machine translation이 효과적일 것이라고 저자는 말했습니다.
참조: (Cho et al., 2014).
* Attention mechanism
* Show and Tell: A Neural Image Caption Generator
Show, Attend, and Tell의 전 버젼이라고 할 수 있습니다. LSTM을 사용하여 image captioning을 한다는 점에서 비슷하지만, 모델에게 image를 하는 시점은 LSTM에 image가 입력될 때 한번 뿐입니다. 그렇기 때문에 sequence가 길어지면 모델은 sequence의 앞부분을 점차 잊어버리게 되는데, 이는 RNN, LSTM 등 sequential 모델의 고질적인 문제점이라고 할 수 있습니다.
#### Idea
이름에서도 알 수 있듯이, Show, Attend, and Tell의 모델은 Show and Tell에 나온 Generator에 attention mechanism을 더한 구조로 되어있습니다. 앞서 언급했듯이, RNN, LSTM 등 sequential 모델의 특성상, sequence가 길어지면 모델은 sequence의 앞부분을 점차 잊어버립니다.
Show, Attend, and Tell에서는 Decoder에 visual attention을 추가함으로써
* sequence가 길어져도 모델이 sequence의 모든 부분을 기억할 수 있게 하고,
* 모델이 그림의 어느 부분에 주목(attention)하여 단어를 captioning했는지 알 수 있어, 해석가능성(Interpretability)을 보장하였으며,
* state-of-the-art 성능을 낼 수 있게 되었습니다.
### 3. Method

1. Encoder: Convolutional feature
CNN으로 구성된 Encoder 는 2D input image를 받아 $$a$$라는 feature vector를 출력합니다. CNN의 마지막 layer가 D개 neuron, L개의 channel로 이루어져있습니다. 따라서 feature extraction을 수행한 결과는 각 $$a\_i$$는 D차원 벡터가 되고, 이러한 벡터들이 총 L개 있는 형태가 됩니다.
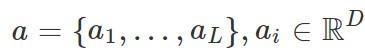 2. Decoder: LSTM with attentiond over the image
2. Decoder: LSTM with attentiond over the image
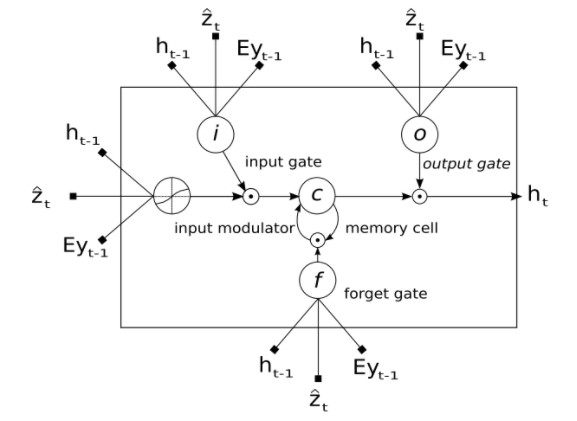 decoder로는 LSTM을 사용합니다. 큰 맥락에서 설명하면, 각 time step t = 1 .. C마다 caption vector $$y$$ 의 element인 한 단어 $$y\_t$$를 output하는 데, 이때 세 요소 $$h\_{t-1}, \hat{z}, Ey\_{t-1}$$를 input으로 반영하겠다는 것이 LSTM 구조를 차용한 핵심 이유입니다. 즉 이전 step의 결과를 input으로 받아 이번 step의 결과를 내는 autoregressive한 방식으로, 단어들을 차례대로 생성하는 Sequential model인 것입니다.
이때 input과 output은 각각의 의미를 가지고 있습니다.
* output $$y\_t$$ = 현재 time stamp에서 만들어낼 단어
* input $$h\_{t-1}$$ = 바로 직전(t-1) 시점의 hidden state
* input $$Ey\_{t-1}$$ = 직전 time stamp에서 만들어낸 단어 $$y\_{t-1}$$를 Embedding matrix E ($$\in R^{m\*K}$$)에 곱하여 embedding 한 벡터
* input $$\hat{z}$$ = CNN encoder output $$a$$ 와 직전 hidden state인 $$h\_{t-1}$$을 이용해 계산한 context vector.
input과 output들을 LSTM의 각 gate와 matching해서 설명하면 다음과 같습니다
decoder로는 LSTM을 사용합니다. 큰 맥락에서 설명하면, 각 time step t = 1 .. C마다 caption vector $$y$$ 의 element인 한 단어 $$y\_t$$를 output하는 데, 이때 세 요소 $$h\_{t-1}, \hat{z}, Ey\_{t-1}$$를 input으로 반영하겠다는 것이 LSTM 구조를 차용한 핵심 이유입니다. 즉 이전 step의 결과를 input으로 받아 이번 step의 결과를 내는 autoregressive한 방식으로, 단어들을 차례대로 생성하는 Sequential model인 것입니다.
이때 input과 output은 각각의 의미를 가지고 있습니다.
* output $$y\_t$$ = 현재 time stamp에서 만들어낼 단어
* input $$h\_{t-1}$$ = 바로 직전(t-1) 시점의 hidden state
* input $$Ey\_{t-1}$$ = 직전 time stamp에서 만들어낸 단어 $$y\_{t-1}$$를 Embedding matrix E ($$\in R^{m\*K}$$)에 곱하여 embedding 한 벡터
* input $$\hat{z}$$ = CNN encoder output $$a$$ 와 직전 hidden state인 $$h\_{t-1}$$을 이용해 계산한 context vector.
input과 output들을 LSTM의 각 gate와 matching해서 설명하면 다음과 같습니다
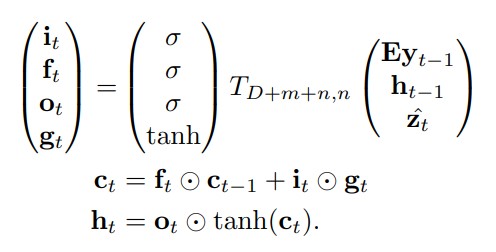 3. Attention
attention mechanism을 통해 결정되는 vector는 context vector $$\hat{z}$$ 입니다. 위에서 언급한대로, CNN encoder output $$a$$ 와 직전 hidden state인 $$h\_{t-1}$$을 이용해 context vector를 계산할 수 있습니다.
Context vector를 구하는 과정을 차례대로 살펴보면,
* CNN encoder output $$a\_i$$와 직전 hidden state $$h\_{t-1}$$를 함수 $$f\_{att}$$에 넣어 $$e\_{ti}$$ 를 구합니다(i= 1 ... L).
이때 $$f\_{att}$$는 weight vector를 계산하기 위한 attention model이며, hard attention과 soft attention으로 나뉩니다. 이는 뒤에서 다시 설명합니다 .
3. Attention
attention mechanism을 통해 결정되는 vector는 context vector $$\hat{z}$$ 입니다. 위에서 언급한대로, CNN encoder output $$a$$ 와 직전 hidden state인 $$h\_{t-1}$$을 이용해 context vector를 계산할 수 있습니다.
Context vector를 구하는 과정을 차례대로 살펴보면,
* CNN encoder output $$a\_i$$와 직전 hidden state $$h\_{t-1}$$를 함수 $$f\_{att}$$에 넣어 $$e\_{ti}$$ 를 구합니다(i= 1 ... L).
이때 $$f\_{att}$$는 weight vector를 계산하기 위한 attention model이며, hard attention과 soft attention으로 나뉩니다. 이는 뒤에서 다시 설명합니다 .
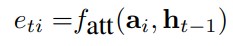 $$e\_{ti}$$ (i= 1 ... L)에 대해서 softmax layer를 거치면 $$\alpha\_{ti}$$ 를 얻습니다.
$$e\_{ti}$$ (i= 1 ... L)에 대해서 softmax layer를 거치면 $$\alpha\_{ti}$$ 를 얻습니다.
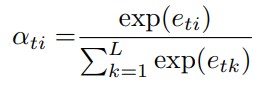 결국 $$\alpha\_t = (\alpha\_{t1}, ..., \alpha\_{tL})$$은 $$a\_1, a\_2, ... a\_L$$ 중 어디에 weight를 주어 attention할 것인지를 결정하는 vector인 것입니다.
그렇게 구한 $$a\_i$$와 $$\alpha\_i$$ 가 $$\phi$$를 거치면 context vector $$\hat{z}$$ 가 됩니다.
결국 $$\alpha\_t = (\alpha\_{t1}, ..., \alpha\_{tL})$$은 $$a\_1, a\_2, ... a\_L$$ 중 어디에 weight를 주어 attention할 것인지를 결정하는 vector인 것입니다.
그렇게 구한 $$a\_i$$와 $$\alpha\_i$$ 가 $$\phi$$를 거치면 context vector $$\hat{z}$$ 가 됩니다.
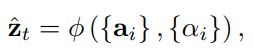 **Note; Attention - Stochastic hard vs Deterministic soft**
Attention model $$f\_{att}$$은 크게 Hard attention과 Soft attention으로 나뉩니다. 이 둘은 마치 0과 1을 사용하여 질적인 차이(유/무)를 구분하는 hard label과 실수 전체 혹은 \[0, 1]에 속하는 실수를 사용하는 soft label 의 용례와 비슷합니다. model이 sum-to-1 vector를 이용하여 어떤 부분에 attend할 것인지 결정할 때, 0과 1로써 deterministic하게 attend하는 hard attention을 사용할 수도 있고, 1을 여러 파트로 분산하는 soft attention을 사용할 수도 있습니다. 이 때문에 빚어지는 차이점은 hidden state의 weight를 계산하는 function이 differentiable한지 여부입니다.
따라서,
* Soft Attention은 Encoder의 hidden state를 미분하여 cost를 구하고 attention mechanism을 통해 gradient가 흘려보내는 방식으로 모델을 학습시킵니다.
* 한편 Hard Attention은 training을 수행할 때, 매 timestamp마다 캡션 모델이 focus해야하는 위치를 random sampling하기 떄문에 모델에 stochasticity가 생기고, 따라서 hidden state의 weight를 계산하는 function이 differentiable하지 않습니다.
만약 weight function이 indifferentiable하다면, end-to-end로 한번에 학습할 수 없고, 도중에 gradient flow를 근사해야하는 번거로움이 생깁니다. 따라서 현재는 gradient를 직접적으로 계산하여 end-to-end 모델에 쓰일 수 있는 soft attention을 더 많이 씁니다.

위 figure에서 hard/soft attention의 경우를 잘 visualization해줍니다. 윗줄은 soft attention, 아랫줄은 hard attention의 경우인데요. 하단의 caption (A, bird, flying, over, ...)을 target하여 attend할 때, soft attention의 경우 상대적으로 caption과 무관한 feature까지 attend하고 있습니다(non-deterministic하므로). hard attention의 경우도 샘플링을 통해 계산되므로, 오롯이 caption의 feature만 target하고 있는 것은 아니지만, soft attention에 비해 훨씬 적은 feature만을 focusing해서 density function 중 많은 부분을 할애하여 attend하고 있습니다.
### 4. Experiment & Result
#### Experimental setup
* Dataset: Flickr8k, Flickr30k, and MS COCO
* Flickr8k/30k: 한 장의 이미지와 그에 상응하는 문장 단위 이미지 설명(sentence-based image description)을 갖춘 데이터셋입니다. Flickr8k는 약 8,000장의 이미지, Flickr30k는 약 30,000장의 이미지가 각 이미지 당 5개 Caption을 가집니다.
* MS COCO: 객체 탐지 (object detection), 세그먼테이션 (segmentation), 키포인트 탐지 (keypoint detection) 등의 task를 목적으로 만들어진 데이터셋입니다
* Baselines: Google NIC, Log Bilinear, CMU/MS Research, MS Research, BRNN
* Evaluation metric: BLEU-1,2,3,4/METEOR metrics
* BLEU (Bilingual Evaluation Understudy) score: translation task에서 대표적으로 사용하는 n-gram based metric입니다. 크게 3가지 요소로 이루어져 있어요.
* Precision: 먼저 reference과 prediction사이에 n-gram이 얼마나 겹치는지 측정합니다.
* Clipping: 같은 단어가 여러 번 나오는 경우 precision을 보정해줍니다. prediction의 중복 단어를 precision에 반영할 때, 아무리 많이 나오더라도 reference의 중복횟수를 초과해서 count되지 않습니다.
* Brevity Penalty: 예컨대 한 단어로 만든 문장이 있을 때 이는 제대로 된 문장이 아니지만, precision이 매우 높게 나옵니다. 따라서 prediction의 길이를 reference 길이로 나눠, 문장길이에 대한 과적합을 보정해줍니다.
* Meteor (Metric for Evaluation of Translation with Explicit ORdering) score: BLEU를 보완해서 나온 metric입니다. 정의는 unigram precision과 recall의 harmonic mean을 통해 계산하는데, 다른 metric과는 달리 exact word matching 방식을 사용합니다. sentence level과 segment level에서 human judgement와 높은 상관관계를 보인다는 점에서, corpus level에서 작동하는 BLEU와 차이가 있습니다.
* Training setup
* encoder CNN: Oxford VGGnet pretrained on ImageNet without finetuning.
* stochastic gradient descent: using adaptive learning rates.
* For the Flickr8k dataset: RMSProp
* Flickr30k/MS COCO dataset: Adam algorithm
#### Result

모든 데이터 셋에서 기존 모델들보다 attention based approach를 썼을 때 BLEU, METEOR score가 훨씬 높았습니다.

Caption generation 모델이 그림 중 어느 부분을 주목하여 단어를 생성했는지 표현하여 captioning process에 해석가능성을 부여하였습니다.
### 5. Conclusion
Show and Tell 논문이 발표되기 이전까지 image captioning은 주로 object detection을 기반으로 했습니다. 주어진 이미지에서 물체를 detect하고 이를 직접 자연어로 연결하는 방식을 택한 것입니다.
Show and Tell 논문은 기존 방법을 탈피하여, end-to-end 방식으로 image captioning을 수행했습니다. 이미지를 CNN으로 인코딩하여 representation vector를 얻고, caption을 LSTM으로 디코딩하여 성능을 크게 향상 시켰습니다.
Show, Attend, and Tell 모델은, Show and tell에서 차용한 구조에 Attention mechanism을 추가한 것과 같습니다. 모든 이미지를 균등하게 보지 않고, 해당 caption이 어느 이미지에 해당하는지 가중치를 분배하여 해석한 것입니다.
다시말해, Attention을 통해
* sequential model의 gradient vanishing 문제를 해결하고,
* attend하는 부분을 눈으로 확인할 수 있다는 점에서 interpretability를 부여했습니다.
#### Take home message (오늘의 교훈)
> 1. Show, Attend, and tell은 vision task에서 Visual attention을 도입했던 시도이며 이 명맥은 지금까지 이어지고 있다!
> 2. 수업 자료에 포함되어 있을 법한 고전 논문을 찾아보는 것도... 가끔은 좋다.
### Author / Reviewer information
#### Author
**이민재 (Lee Min Jae)**
* M.S. student, KAIST AI
*
#### Reviewer
1. 양소영: 카이스트 AI 대학원 석사과정
2. 박여정: 카이스트 AI 대학원 석사과정
3. 오상윤: 카이스트 기계공학과 박사과정
### Reference & Additional materials
Show, Attend, and Tell paper
On the 'show, attend, and tell' model
An implementation code with Pytorch (unofficial)
On attention part
On MS COCO dataset
On BLEU SCORE
**Note; Attention - Stochastic hard vs Deterministic soft**
Attention model $$f\_{att}$$은 크게 Hard attention과 Soft attention으로 나뉩니다. 이 둘은 마치 0과 1을 사용하여 질적인 차이(유/무)를 구분하는 hard label과 실수 전체 혹은 \[0, 1]에 속하는 실수를 사용하는 soft label 의 용례와 비슷합니다. model이 sum-to-1 vector를 이용하여 어떤 부분에 attend할 것인지 결정할 때, 0과 1로써 deterministic하게 attend하는 hard attention을 사용할 수도 있고, 1을 여러 파트로 분산하는 soft attention을 사용할 수도 있습니다. 이 때문에 빚어지는 차이점은 hidden state의 weight를 계산하는 function이 differentiable한지 여부입니다.
따라서,
* Soft Attention은 Encoder의 hidden state를 미분하여 cost를 구하고 attention mechanism을 통해 gradient가 흘려보내는 방식으로 모델을 학습시킵니다.
* 한편 Hard Attention은 training을 수행할 때, 매 timestamp마다 캡션 모델이 focus해야하는 위치를 random sampling하기 떄문에 모델에 stochasticity가 생기고, 따라서 hidden state의 weight를 계산하는 function이 differentiable하지 않습니다.
만약 weight function이 indifferentiable하다면, end-to-end로 한번에 학습할 수 없고, 도중에 gradient flow를 근사해야하는 번거로움이 생깁니다. 따라서 현재는 gradient를 직접적으로 계산하여 end-to-end 모델에 쓰일 수 있는 soft attention을 더 많이 씁니다.

위 figure에서 hard/soft attention의 경우를 잘 visualization해줍니다. 윗줄은 soft attention, 아랫줄은 hard attention의 경우인데요. 하단의 caption (A, bird, flying, over, ...)을 target하여 attend할 때, soft attention의 경우 상대적으로 caption과 무관한 feature까지 attend하고 있습니다(non-deterministic하므로). hard attention의 경우도 샘플링을 통해 계산되므로, 오롯이 caption의 feature만 target하고 있는 것은 아니지만, soft attention에 비해 훨씬 적은 feature만을 focusing해서 density function 중 많은 부분을 할애하여 attend하고 있습니다.
### 4. Experiment & Result
#### Experimental setup
* Dataset: Flickr8k, Flickr30k, and MS COCO
* Flickr8k/30k: 한 장의 이미지와 그에 상응하는 문장 단위 이미지 설명(sentence-based image description)을 갖춘 데이터셋입니다. Flickr8k는 약 8,000장의 이미지, Flickr30k는 약 30,000장의 이미지가 각 이미지 당 5개 Caption을 가집니다.
* MS COCO: 객체 탐지 (object detection), 세그먼테이션 (segmentation), 키포인트 탐지 (keypoint detection) 등의 task를 목적으로 만들어진 데이터셋입니다
* Baselines: Google NIC, Log Bilinear, CMU/MS Research, MS Research, BRNN
* Evaluation metric: BLEU-1,2,3,4/METEOR metrics
* BLEU (Bilingual Evaluation Understudy) score: translation task에서 대표적으로 사용하는 n-gram based metric입니다. 크게 3가지 요소로 이루어져 있어요.
* Precision: 먼저 reference과 prediction사이에 n-gram이 얼마나 겹치는지 측정합니다.
* Clipping: 같은 단어가 여러 번 나오는 경우 precision을 보정해줍니다. prediction의 중복 단어를 precision에 반영할 때, 아무리 많이 나오더라도 reference의 중복횟수를 초과해서 count되지 않습니다.
* Brevity Penalty: 예컨대 한 단어로 만든 문장이 있을 때 이는 제대로 된 문장이 아니지만, precision이 매우 높게 나옵니다. 따라서 prediction의 길이를 reference 길이로 나눠, 문장길이에 대한 과적합을 보정해줍니다.
* Meteor (Metric for Evaluation of Translation with Explicit ORdering) score: BLEU를 보완해서 나온 metric입니다. 정의는 unigram precision과 recall의 harmonic mean을 통해 계산하는데, 다른 metric과는 달리 exact word matching 방식을 사용합니다. sentence level과 segment level에서 human judgement와 높은 상관관계를 보인다는 점에서, corpus level에서 작동하는 BLEU와 차이가 있습니다.
* Training setup
* encoder CNN: Oxford VGGnet pretrained on ImageNet without finetuning.
* stochastic gradient descent: using adaptive learning rates.
* For the Flickr8k dataset: RMSProp
* Flickr30k/MS COCO dataset: Adam algorithm
#### Result

모든 데이터 셋에서 기존 모델들보다 attention based approach를 썼을 때 BLEU, METEOR score가 훨씬 높았습니다.

Caption generation 모델이 그림 중 어느 부분을 주목하여 단어를 생성했는지 표현하여 captioning process에 해석가능성을 부여하였습니다.
### 5. Conclusion
Show and Tell 논문이 발표되기 이전까지 image captioning은 주로 object detection을 기반으로 했습니다. 주어진 이미지에서 물체를 detect하고 이를 직접 자연어로 연결하는 방식을 택한 것입니다.
Show and Tell 논문은 기존 방법을 탈피하여, end-to-end 방식으로 image captioning을 수행했습니다. 이미지를 CNN으로 인코딩하여 representation vector를 얻고, caption을 LSTM으로 디코딩하여 성능을 크게 향상 시켰습니다.
Show, Attend, and Tell 모델은, Show and tell에서 차용한 구조에 Attention mechanism을 추가한 것과 같습니다. 모든 이미지를 균등하게 보지 않고, 해당 caption이 어느 이미지에 해당하는지 가중치를 분배하여 해석한 것입니다.
다시말해, Attention을 통해
* sequential model의 gradient vanishing 문제를 해결하고,
* attend하는 부분을 눈으로 확인할 수 있다는 점에서 interpretability를 부여했습니다.
#### Take home message (오늘의 교훈)
> 1. Show, Attend, and tell은 vision task에서 Visual attention을 도입했던 시도이며 이 명맥은 지금까지 이어지고 있다!
> 2. 수업 자료에 포함되어 있을 법한 고전 논문을 찾아보는 것도... 가끔은 좋다.
### Author / Reviewer information
#### Author
**이민재 (Lee Min Jae)**
* M.S. student, KAIST AI
*
#### Reviewer
1. 양소영: 카이스트 AI 대학원 석사과정
2. 박여정: 카이스트 AI 대학원 석사과정
3. 오상윤: 카이스트 기계공학과 박사과정
### Reference & Additional materials
Show, Attend, and Tell paper
On the 'show, attend, and tell' model
An implementation code with Pytorch (unofficial)
On attention part
On MS COCO dataset
On BLEU SCORE